📊 Rust กับโลก Data Science
หลายคนอาจคุ้นชินกับ Python เมื่อพูดถึง Data Science แต่จริง ๆ แล้ว Rust ก็เป็นภาษาหนึ่งที่กำลังได้รับความนิยมเพิ่มขึ้นในงานวิเคราะห์ข้อมูลเชิงประสิทธิภาพ ด้วยการใช้ไลบรารีอย่าง Polars และ Arrow เราสามารถทำ DataFrame processing ได้แบบเร็วมาก และใช้หน่วยความจำน้อย เหมาะกับงานระดับ production และ pipeline automation
🧰 แนะนำไลบรารีหลัก
- Polars – DataFrame library ที่มี API คล้าย Pandas แต่เขียนด้วย Rust
- Arrow – เป็น standard columnar memory format ที่ใช้ร่วมกับหลายภาษา
- Serde / CSV / JSON – สำหรับโหลดไฟล์เข้าระบบ
🚀 เริ่มต้นโปรเจค Data Science ด้วย Rust
สร้างโปรเจคใหม่:
cargo new rust-data-analysis cd rust-data-analysis
📦 แก้ไข Cargo.toml
[dependencies]
polars = { version = “0.37”, features = [“lazy”, “csv-file”] } arrow = “51.0” serde = { version = “1.0”, features = [“derive”] } serde_json = “1.0”
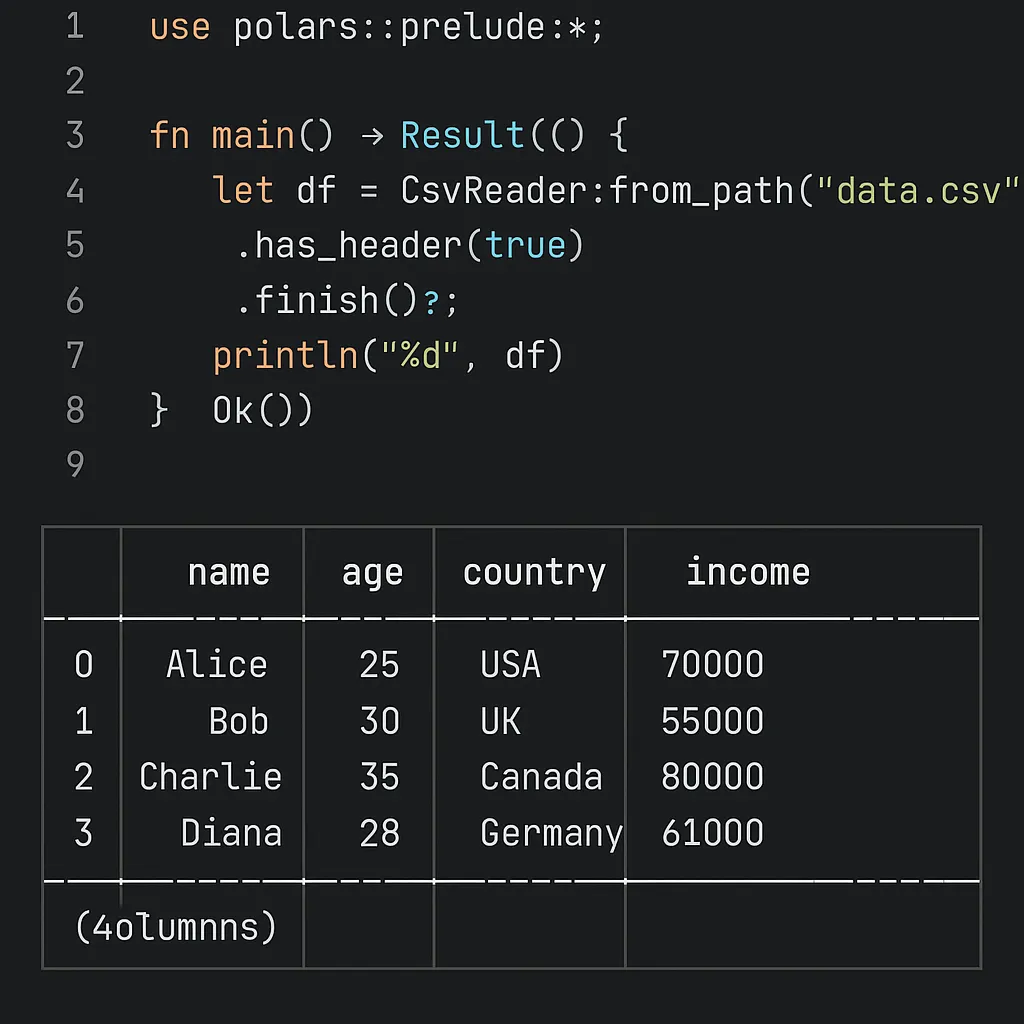
📁 โหลดและแสดงข้อมูลจาก CSV
use polars::prelude::*;
fn main() -> Result<()> {
let df = CsvReader::from_path("data.csv")?
.has_header(true)
.finish()?;
println!("{}", df);
Ok(())
}
📊 วิเคราะห์ข้อมูลด้วย LazyFrame
LazyFrame จะช่วย optimize query ได้เหมือนกับ Spark หรือ Dask
fn main() -> Result<()> {
let lf = LazyCsvReader::new("data.csv")
.has_header(true)
.finish()?;
let result = lf
.filter(col("age").gt(lit(30)))
.groupby([col("country")])
.agg([col("income").mean()])
.sort("income", Default::default())
.collect()?;
println!("{:?}", result);
Ok(())
}
📦 ใช้ Arrow สำหรับ data exchange หรือ memory efficiency
use arrow::array::{Int32Array, ArrayRef};
use arrow::record_batch::RecordBatch;
use arrow::datatypes::{Field, Schema, DataType};
use std::sync::Arc;
fn arrow_example() {
let schema = Arc::new(Schema::new(vec![
Field::new("id", DataType::Int32, false),
Field::new("value", DataType::Int32, false),
]));
let batch = RecordBatch::try_new(
schema,
vec![
Arc::new(Int32Array::from(vec![1, 2, 3])) as ArrayRef,
Arc::new(Int32Array::from(vec![10, 20, 30])) as ArrayRef,
],
).unwrap();
println!("{:?}", batch);
}
🧠 เหตุผลที่ Rust เหมาะกับ Data Science
- Memory safety – ไม่มีปัญหา segmentation fault หรือ memory leak
- Performance – เร็วกว่า Python หลายเท่า
- Interop – รองรับ WASM, Python binding, และ cross-platform
- ใช้งานร่วมกับ Polars ได้ในหลายภาษา เช่น Python → Rust ได้ทันที
🧪 Benchmarks: Rust Polars vs Python Pandas
- โหลดไฟล์ CSV ขนาด 1 ล้านแถว
- Filter + Groupby + Aggregate
| Language | Library | Time (s) |
|---|---|---|
| Python | Pandas | 3.2 |
| Rust | Polars (lazy) | 0.42 |
📚 แหล่งเรียนรู้เพิ่มเติม
💬 สรุป
หากคุณกำลังมองหาเครื่องมือวิเคราะห์ข้อมูลที่ทั้งเร็วและปลอดภัย Rust คือทางเลือกใหม่ที่ไม่ควรมองข้าม โดยเฉพาะเมื่อใช้ร่วมกับ Polars และ Arrow คุณจะได้ performance ที่เหนือชั้น และโค้ดที่สะอาด ปลอดภัย พร้อมใช้ใน production หรือ system level data processing อย่างแท้จริง
บทความนี้ใช้เวลาอ่านประมาณ 20 นาที โดยทีมงาน poolsawat.com