การออกแบบ Database Schema ที่ดีคือหัวใจสำคัญของการทำงานกับฐานข้อมูล เพราะมีผลโดยตรงต่อความถูกต้องของข้อมูล (Data Integrity), ความเร็วของ Query และการขยายระบบในอนาคต หนึ่งในหัวข้อที่นักพัฒนามักต้องเจอคือการตัดสินใจเลือกใช้ Normalization หรือ Denormalization บทความนี้จะเจาะลึกทั้งสองแนวทาง พร้อมตัวอย่างการใช้งานจริง
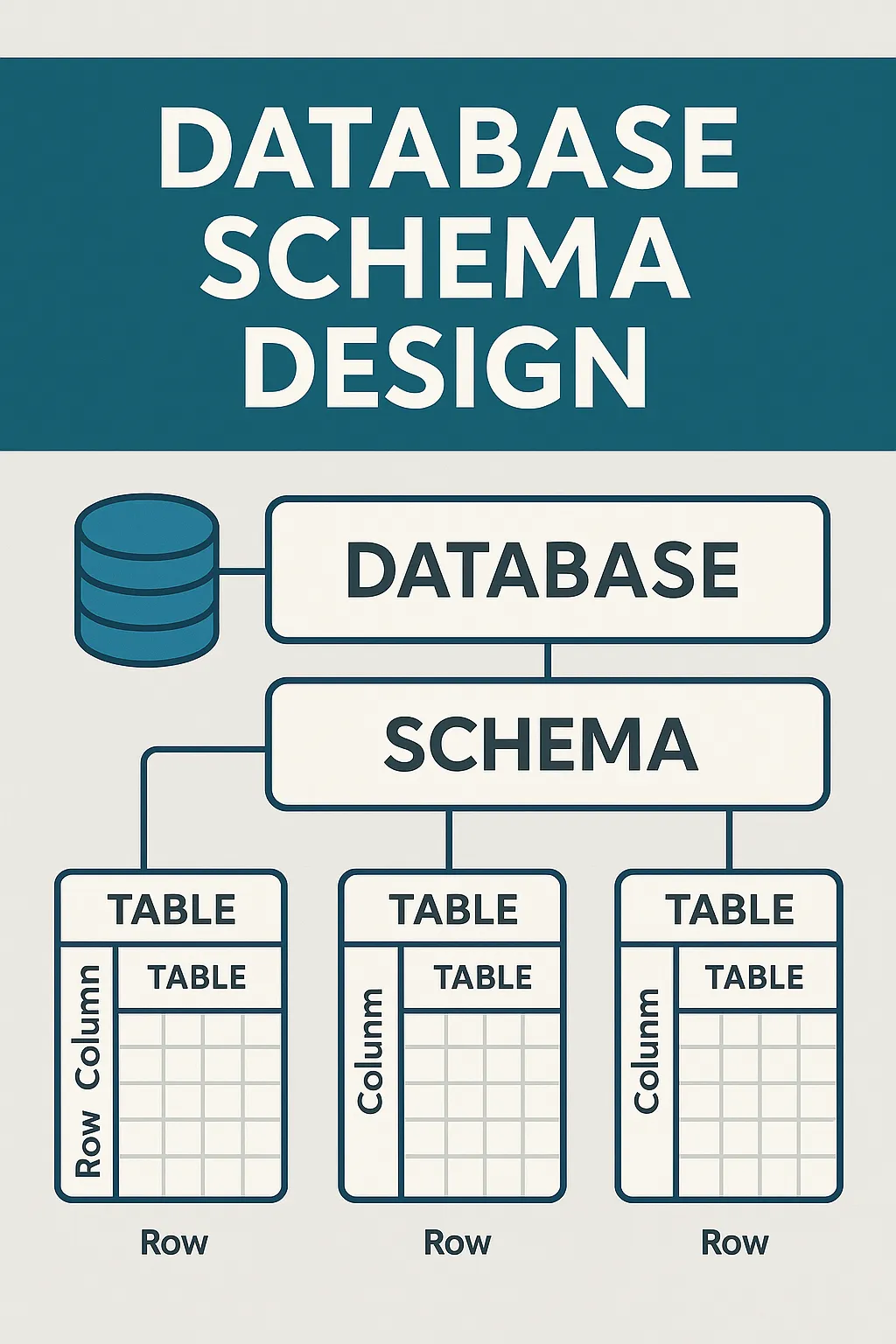
Database Schema คืออะไร?
Database Schema คือโครงสร้างที่กำหนดวิธีจัดเก็บข้อมูลในฐานข้อมูล ประกอบไปด้วย Table, Column, Relationship และ Constraints ต่าง ๆ การออกแบบ Schema ที่ดีช่วยให้ข้อมูลไม่ซ้ำซ้อน (redundant) และ Query ได้เร็วขึ้น
Normalization คืออะไร?
Normalization คือกระบวนการออกแบบฐานข้อมูลโดยแยกข้อมูลออกเป็นตารางย่อย เพื่อหลีกเลี่ยงการซ้ำซ้อน และเพื่อให้ข้อมูลมีความถูกต้องสอดคล้องกัน (Data Consistency)
ตัวอย่างการ Normalize
สมมติว่ามีตาราง employees ที่เก็บข้อมูลแบบยังไม่ Normalize:
-- ตารางก่อน Normalize CREATE TABLE employees_raw ( id SERIAL PRIMARY KEY, name VARCHAR(100), department VARCHAR(100), department_location VARCHAR(100) );
หลังจาก Normalize เราจะแยกตาราง Department ออกมา:
CREATE TABLE departments ( dept_id SERIAL PRIMARY KEY, dept_name VARCHAR(100), dept_location VARCHAR(100) ); CREATE TABLE employees ( id SERIAL PRIMARY KEY, name VARCHAR(100), dept_id INT REFERENCES departments(dept_id) );
ข้อดีของ Normalization
- ลดความซ้ำซ้อนของข้อมูล
- อัปเดตข้อมูลครั้งเดียวกระทบทุกที่
- โครงสร้างชัดเจน ใช้ง่ายต่อการดูแล
ข้อเสียของ Normalization
- Query ซับซ้อนขึ้น (ต้อง Join หลาย Table)
- อาจทำให้ Performance ช้าลงในบางกรณี
Denormalization คืออะไร?
Denormalization คือการออกแบบฐานข้อมูลให้ข้อมูลบางส่วนซ้ำซ้อน โดยการรวมข้อมูลจากหลายตารางเข้าด้วยกัน เพื่อลดจำนวนการ Join และเพิ่มความเร็วในการ Query
ตัวอย่างการ Denormalize
-- ตารางหลัง Denormalize CREATE TABLE employees_full ( id SERIAL PRIMARY KEY, name VARCHAR(100), dept_name VARCHAR(100), dept_location VARCHAR(100) );
ข้อดีของ Denormalization
- Query เร็วขึ้น (ลดการ Join)
- โครงสร้างง่ายสำหรับการ Report
ข้อเสียของ Denormalization
- มีข้อมูลซ้ำซ้อน (Redundant Data)
- อัปเดตยากขึ้น (ต้องอัปเดตหลายที่)
Normalization vs Denormalization
ไม่มีคำตอบตายตัวว่าควรเลือกแบบไหน ขึ้นอยู่กับบริบทการใช้งาน เช่น ระบบ Online Transaction Processing (OLTP) มักใช้ Normalization ส่วนระบบ Data Warehouse ที่เน้น Query เร็ว อาจใช้ Denormalization
| หัวข้อ | Normalization | Denormalization |
|---|---|---|
| โครงสร้าง | ซับซ้อน ต้อง Join | ง่าย ข้อมูลรวมกัน |
| ประสิทธิภาพ | ดีในการเขียนข้อมูล | ดีในการอ่านข้อมูล |
| ความซ้ำซ้อน | ต่ำ | สูง |

กรณีศึกษา
– ระบบธนาคาร (Banking System): ต้องการความถูกต้องสูง → ใช้ Normalization – ระบบ Analytics / Big Data: เน้น Query เร็ว → ใช้ Denormalization – ระบบ E-commerce: ผสมผสาน ทั้ง Normalize สำหรับ Transaction และ Denormalize สำหรับ Report
สรุป
การออกแบบ Database Schema ที่ดีต้องเข้าใจทั้ง Normalization และ Denormalization ไม่ควรยึดติดเพียงแนวทางใดแนวทางหนึ่ง แต่ควรผสมผสานตามความเหมาะสม เพื่อให้ได้ทั้งความถูกต้องของข้อมูลและประสิทธิภาพของระบบ
SEO Keywords
Database Schema,Database Normalization,Database Denormalization,ออกแบบ Database,SQL Schema,Normalization vs Denormalization,สอน Database,Data Redundancy,Query Optimization